计组P5设计文档
P5建议:可以在P4的基础上先搭建没有转发、阻塞的流水线CPU,确认功能完善后逐步添加阻塞、转发通路。对于P5,转发与阻塞情况不多,也可采用列举法,后期改为TIME
设计要求
- 处理器应支持如下指令集:{ add, sub, ori, lw, sw, beq, lui, jal, jr, nop },为五级流水线设计。
- 流水线的设计以追求性能为第一目标,因此必须尽最大可能支持转发以解决数据冒险。这一点在本 project 的最终成绩中所占比重较大,课上测试时会通过测试程序所运行的总周期数进行判定,望大家慎重对待。
- 对于 b 类和 j 类指令, 流水线设计必须支持延迟槽,因此设计需要注意使用 PC@D + 8或PC@I + 4。
- 为了解决数据冒险而设计的转发数据来源必须是某级流水线寄存器,不允许对功能部件的输出直接进行转发。
- 指令存储器(IM,instruction memory)和数据存储器(DM,data
memory)要求如下:
- IM:容量为 16KiB(4096 × 32bit)。
- DM:容量为 12KiB(3072 × 32bit)。
- PC 的初始地址为 0x00003000,和 Mars 中我们要求设置的代码初始地址相同。
- 最外层的 mips 模块的文件名必须为 mips.v ,该文件中的 module 也必须命名为 mips 。
模块规格
架构
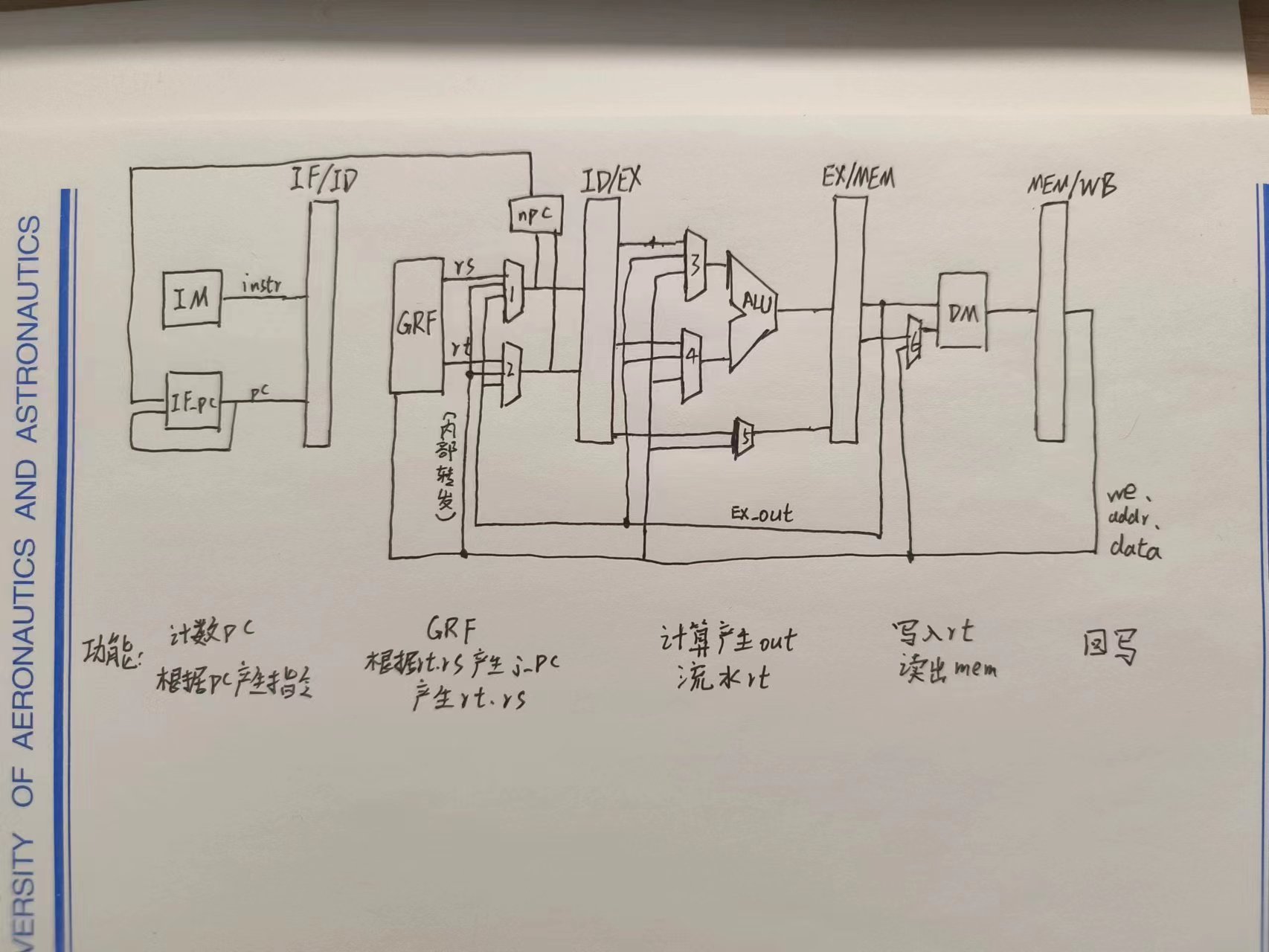
命名规则
流水线信号共5级,IF/ID ID/EX EX/MEM MEM/WB,两个寄存器间的信号用
级别_数据/功能(_去向) 命名。
控制器设计
指令解读
| 指令 | 31-26 | 25-21 | 20-16 | 15-11 | 10-6 | 5-0 | 解释 |
|---|---|---|---|---|---|---|---|
| add | 000000 | rs | rt | rd | 00000 | 100000 | rd=rs+rt |
| sub | 000000 | rs | rt | rd | 00000 | 100010 | rd=rs-rt |
| ori | 001101 | rs | rt | im | im | im | rt=rs|im |
| lw | 100011 | base | rt | offset | offset | offset | rt=mem(base+of) |
| sw | 101011 | base | rt | offset | offset | offset | mem(base+of)=rt |
| beq | 000100 | rs | rt | offset | offset | offset | PC+=4+of00? |
| lui | 001111 | 00000 | rt | im | im | im | rt=im(0*16) |
| jal | 000011 | index | index | index | index | index | 较为复杂 |
| jr | 000000 | rs | 0 | 0 | 0 | 001000 | PC=rs |
jal:$31=PC+4,PC=PC[31:28]+index00
共有信号:
| 变量 | 方向 | 位宽 | 解释 | 来源/去向 |
|---|---|---|---|---|
| clk | in | 1 | 时钟信号 | 顶层输入 |
| rst | in | 1 | 复位信号 | 顶层输入 |
| xx_pc | in | [31:0] | 当前级的pc | 上一级 |
| xx_pc_yy | out | [31:0] | 要传给下一级的pc | 下一级yy(WB无) |
| xx_instr | in | [31:0] | 当前级的指令 | 上一级 |
| xx_instr_yy | out | [31:0] | 要传给下一级的指令 | 下一级yy(WB无) |
IF
接口
| 变量 | 方向 | 位宽 | 解释 | 来源/去向 |
|---|---|---|---|---|
| stall | in | 1 | 阻塞信号,使pc保持不变 | staller |
| IF_j | in | 1 | 是否跳转 | ID_j_IF |
| IF_pc4 | in | [31:0] | 跳转指令地址 | ID_pc_IF |
内部变量
1 | |
ID
接口
| 变量 | 方向 | 位宽 | 解释 | 来源/去向 |
|---|---|---|---|---|
| stall | in | 1 | 阻塞信号,清空D级 | staller |
| WB_pc_ID | in | [31:0] | 写入指令的pc | WB_pc_ID |
| ID_we | in | 1 | 寄存器写入信号 | WB_we_ID |
| ID_addr | in | [4:0] | 要写入的寄存器 | WB_addr_ID |
| ID_data | in | [31:0] | 要写入的值 | WB_data_ID |
| ID_rs_sign | in | [2:0] | 转发选择,0为原值 | |
| ID_rt_sign | in | [2:0] | 转发选择,0为原值 | |
| ID_rs_data | in | [31:0] | 转发值 | EX_out,EX_data_WB,MEM_data_WB |
| ID_rt_data | in | [31:0] | 转发值 | |
| ID_rs_base | out | [31:0] | rs寄存器的值 | EX_rs_base |
| ID_rt | out | [31:0] | rt寄存器的值 | EX_rt |
| ID_j_IF | out | 1 | 跳转指示信号 | IF_j |
| ID_pc_IF | out | [31:0] | 跳转指令地址 | IF_pc4 |
内部变量
1 | |
EX
| 变量 | 方向 | 位宽 | 解释 | 来源/去向 |
|---|---|---|---|---|
| EX_rs_base | in | [31:0] | rs寄存器的值 | ID_rs_base |
| EX_rt_use | in | [31:0] | 参与运算的rt寄存器的值,可能从转发处来 | |
| EX_rt | in | [31:0] | 传递rt供sw写入的值,也可能从转发处来 | |
| EX_out | out | [31:0] | 运算结果 | MEM_addr |
| EX_rt_MEM | out | [31:0] | rt寄存器的值 | MEM_data |
MEM
接口
| 变量 | 方向 | 位宽 | 解释 | 来源/去向 |
|---|---|---|---|---|
| MEM_addr | in | [31:0] | 要写入的地址 | EX_out |
| MEM_data | in | [31:0] | 要写入的数据 | EX_rt_MEM |
| MEM_data_WB | out | [31:0] | 内存中读出的数据 | WB_lw_data |
| EX_data_WB | out | [31:0] | 运算结果 | WB_alu_data |
内部变量
1 | |
WB
输出均不是reg型
| 变量 | 方向 | 位宽 | 解释 | 来源/去向 |
|---|---|---|---|---|
| WB_lw_data | in | [31:0] | 从内存取出的数 | MEM_data_WB |
| WB_alu_data | in | [31:0] | 运算结果 | EX_data_WB |
| WB_we_ID | out | 1 | 寄存器写入信号 | ID_we |
| WB_addr_ID | out | [4:0] | 要写入的寄存器地址 | ID_addr |
| WB_data_ID | out | [31:0] | 要写入寄存器的值 | ID_data |
冒险处理
\(T_{use}\) 与 \(T_{new}\) 的计算
指令分类
calr——2个use(rs,rt),一个new(rd)
add、sub
cali——1个use(rs),一个new(rt)
ori、lui
lw——1个use(rs/base),一个new(rt)
lw
sw——2个use(rs,rt),无new
sw
j_rs——1个use(rs)
jr、beq
j_rt——1个use(rt)
beq
jal——无法分类
其中,beq从属于两种
列表
| 指令 | 类型 | \(T_{use}\) | 转发接口 | \(E\_T_{new}\) | 提供接口 |
|---|---|---|---|---|---|
| add | calr | 1(rs,rt) | ID_rs_base_EX,ID_rt_EX | 1(rd) | EX_out |
| sub | calr | 1(rs,rt) | ID_rs_base_EX,ID_rt_EX | 1(rd) | EX_out |
| ori | cali | 1(rs) | ID_rs_base_EX | 1(rt) | EX_out |
| lw | lw | 1(base) | ID_rs_base_EX | 2(rt) | WB_data_ID |
| sw | sw | 1(rs),2(rt) | ID_rs_base_EX,EX_rt_MEM | \ | \ |
| beq | j_rs,j_rt | 0(rs,rt) | ID_rs_data,ID_rt_data | \ | \ |
| lui | cali | \ | \ | 1(rt) | EX_out |
| jal | j | \ | \ | 1($31) | EX_out |
| jr | j_rs | 0(rs) | ID_rs_data | \ | \ |
暂停
阻塞分类
总原则: \(T_{use}<E\_T_{new}\) 、 \(T_{use}<M\_T_{new}\) 、地址相同
大致有0<1、0<2、1<2、0<2(M级)四种类型,均需比较地址
执行操作
若需要阻塞,则
- 冻结IF/ID
- 清除ID/EX
- 禁止PC
转发
接口
见表格
注意事项
- 从W级转发到D级,采用D级内部转发(如beq)
- 从W级转发到E、M级,可利用WB的信号直接判断
- MEM写入内存的rt值从D到E再到M,要经过2次转发(如lw $3,0($0) sw $3,0($3),因为阻塞了一次,W级产生的数据没办法转发到M级,只能是sw在E级时把W级的lw产生的数据转发)
- 转发时如果地址是0寄存器应剔除
遇到的bug&修复历史
jr忘记加到阻塞里
lw写入的是rt不是rd,阻塞判断错了
先lw,后sw发生阻塞时,不能及时转发sw需要、lw产生的rt值
1 | |
加指令:改const、改阻塞、改转发、
添加指令
- 添加到const里
- 分类,想想有无新的转发通路/阻塞
- cal:修改EX计算过程、添加WB回写信号,加入相关阻塞指令中(带cal的),加入相关转发指令中(同上,注意供需接口都有)。
- lw:修改EX计算过程、添加WB回写信号,……
- sw:修改EX计算过程、MEM写入,……但是注意“注意事项3”,修改rt在E级的转发
- j_rs:
- j_rt:修改ID跳转判断与跳转地址计算,加入阻塞、转发指令
- jal:修改ID跳转判断与跳转地址计算、EX算pc等、WB回写信号,阻塞转发
- 在阻塞和转发中分别添加相应值,注意“注意事项3”
思考题
1、我们使用提前分支判断的方法尽早产生结果来减少因不确定而带来的开销,但实际上这种方法并非总能提高效率,请从流水线冒险的角度思考其原因并给出一个指令序列的例子。
提前分支判断使得beq的 \(T_{use}\) 为0,很容易发生阻塞,如
1 | |
如果不提前判断,则可以使用转发解决(但这样好像会多流水一级?)
2、因为延迟槽的存在,对于 jal 等需要将指令地址写入寄存器的指令,要写回 PC + 8,请思考为什么这样设计?
jal执行后会无条件执行下一句(pc+4),但jr $ra执行时不会再执行延迟槽中的内容,因此是pc+8
3、我们要求大家所有转发数据都来源于流水寄存器而不能是功能部件(如 DM 、 ALU ),请思考为什么?
来自寄存器的输出是稳定的,而功能部件可能输出不稳定
4、我们为什么要使用 GPR 内部转发?该如何实现?
为了将来自W级的输出及时写入寄存器(或及时使用)。实现见代码
5、我们转发时数据的需求者和供给者可能来源于哪些位置?共有哪些转发数据通路?
见“冒险处理”
6、在课上测试时,我们需要你现场实现新的指令,对于这些新的指令,你可能需要在原有的数据通路上做哪些扩展或修改?提示:你可以对指令进行分类,思考每一类指令可能修改或扩展哪些位置。
见“添加指令”
7、确定你的译码方式,简要描述你的译码器架构,并思考该架构的优势以及不足。
分布式译码,每一级流水指令即可,无需流水控制信号,通过宏定义根据指令执行操作
不足:加指令时需要修改的部件较多
让我想想
测试部分
part1——P4的数据测试
1 | |
part2——冒险测试
\(A_9^4\)?
1 | |
把mips.v里的转发、阻塞写到每个模块里,每个模块只需要针对当前指令给出addr和Tnew,ID给出Tuse
为什么DM的rt需要在E、M级2次转发?
大概因为sw在DM才用,lw的数据W级才有,错开就?